
What I Built
A system that automatically monitors what’s happening in B2B SaaS companies across Europe — funding rounds, product launches, hiring activity, market moves — and turns that noise into structured, scannable insights.
Instead of manually following dozens of news sources and trying to spot patterns, this tool collects signals, extracts what matters, adds business context, and delivers it in a format that’s actually useful.
You can see the live result here: european-saas-signals.lovable.app
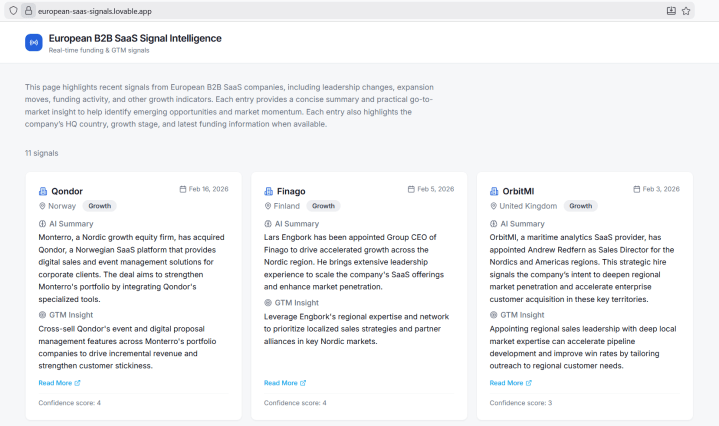
Why This Exists
In B2B marketing and GTM work, signals are everywhere. The problem isn’t access to information — it’s that the information is fragmented, noisy, and hard to prioritize.
I built this to explore a simple question: can I create a system that does the tedious monitoring work automatically, so I can focus on acting on insights rather than hunting for them?
This was also a learning project. I wanted to understand how AI tools actually work when you approach them as a marketer, not an engineer.
The Tools
- Make.com — The automation layer that connects everything. It orchestrates the entire workflow: collecting signals, sending them to AI, storing the results.
- RSS feeds — The signal source. Structured, predictable, easy to work with. I started here because it let me focus on system design rather than fighting messy data.
- OpenAI — The AI extraction layer. It reads raw articles and pulls out the relevant facts: what happened, who’s involved, why it matters.
- Airtable — The database. Stores everything in a structured format so I can filter, compare, and build on top of it later.
- Lovable — The frontend. A no-code tool for building web interfaces, used to turn the backend data into something anyone can open and explore.
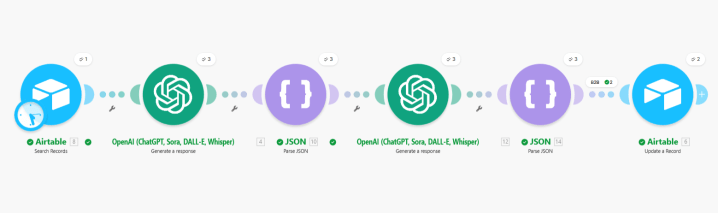
How The Data Flows
- Signal ingestion — Make.com pulls updates from RSS feeds automatically.
- AI extraction — Each update gets sent to OpenAI, which extracts the core event and produces a summary optimized for scanning.
- Context enrichment — The system adds business context: estimated company stage, geographic focus, B2B vs B2C classification.
- Confidence scoring — Not all AI outputs are equally reliable. The system flags how much trust to place in each signal based on source quality and data clarity.
- Structured storage — The JSON output maps directly into Airtable fields, making storage clean and queryable.
- Interface — Lovable pulls from Airtable and displays the signals in a clean, public webpage.
I had two scenarios in Make, this image is from second one.
Why I Made Certain Choices
Starting with RSS feeds — They’re boring but reliable. I wanted to learn system design, not spend hours cleaning messy data. Once the core logic works, adding messier sources is easier.
Adding confidence scores — AI outputs shouldn’t be treated as truth. By flagging reliability, the system helps users make decisions rather than making decisions for them.
Storing everything in Airtable — Even if I change how I display results later, the underlying data is preserved. This also lets me iterate on logic without starting over each time.
Planning Lovable prompts in ChatGPT first — Lovable’s free plan burns through credits fast. By crafting my requests carefully before touching the tool, I avoided expensive iteration loops.
What I Learned
Debugging is where real learning happens. Early outputs were too generic, classifications were inconsistent, edge cases broke things. Each fix taught me something about how these systems actually behave.
I didn’t trust ChatGPT blindly — it forgets things and sometimes lacks current information. But having it as a thinking partner at every step made the whole project possible. For the next project I will try Claude.
You don’t need to be an engineer to build intelligent systems. But you do need structured thinking and patience for iteration.
Time and Cost
About 20 hours total across both the backend system and the frontend interface. All tools were free versions except ChatGPT (€8/month) and a few euros of OpenAI API credits. I kept data volumes low deliberately — enough to validate the system works, without wasting energy or money.
One practical note: reserve uninterrupted blocks of at least 2 hours. You can’t build something like this in 30-minute chunks between meetings.
What’s Next
This project stays a work in progress. Possible directions: more signal types, better filtering, expanding data sources.
The confidence boost from shipping something real was worth every debugging session. I already have ideas for what to build next.
~~~
Learning continues… ✨
